









Meta’s open-source project, Code Llama, is poised to bring forth a significant wave of secondary innovations. WizardCoder managed to outperform GPT-4 with a winning rate of 73.2%. OpenAI employees revealed that Llama 3 retains its open-source nature even while being capable of playing against GPT-4.
Merely two days after its launch, Code Llama once again ignited the revolution in AI coding.
Recall the enigmatic variant Unnatural Code Llama mentioned in the Code Llama paper by Meta, which has the potential to match GPT-4’s capabilities.
Sebastian, a prominent figure, elucidated in his blog: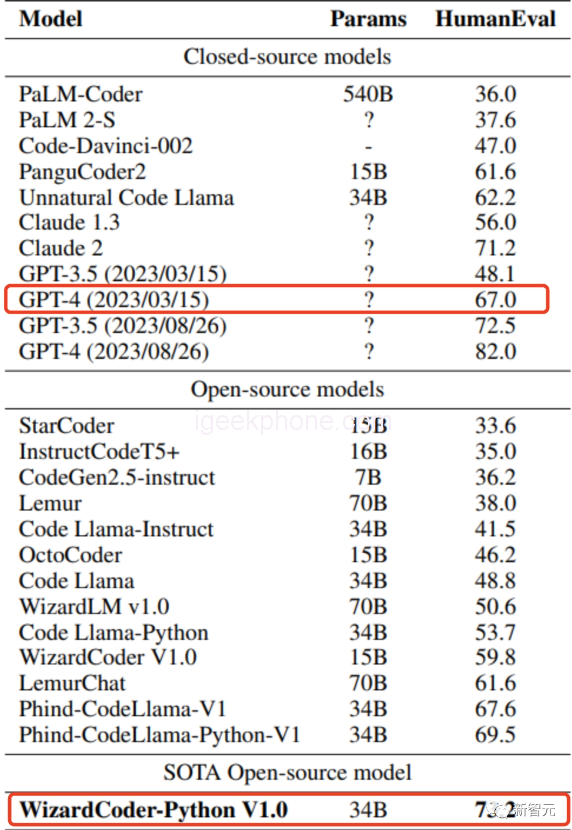
“It is a fine-tuned version of Code Llama-Python 34B with 15,000 non-natural language instructions.”
By subtly concealing this intricate information in the paper, Meta seemingly aimed to suggest to the open-source community that Code Llama holds immense promise—encouraging further fine-tuning.
Hence, recently, WizardCoder 34B, refined based on Code Llama, directly triumphed over GPT-4 on the HumanEval benchmark.
To be specific, WizardCoder surpassed GPT-4’s March edition (67%) with an impressive win rate of 73.2%.
Furthermore, WizardCoder 34B’s performance exceeds the latest iterations of GPT-3.5 and Claude 2.
The programming model WizardCoder was introduced in June by Microsoft and Hong Kong Baptist University, with an upcoming fine-tuned 13B/7B version on the horizon.
According to Nvidia’s top scientist, Jim Fan, this essentially represents an open version of “Unnatural Code Llama.”
While the benchmark data appears promising, it’s important to note that HumanEval solely assesses a limited spectrum and might be prone to overfitting. Evaluating the data in natural scenarios is of paramount significance. Coding benchmarks warrant significant upgrades.
Could there be another enigmatic version of Code Llama?
Last Friday, Meta officially released three versions of Code Llama.
During evaluations on the HumanEval and MBPP benchmarks, a version that had not been officially mentioned by Meta—Unnatural Code Llama—came to light.
This mysterious rendition achieved a performance score of 62.2% on HumanEval pass@1.
Conversely, the freshly refined WizardCoder 34B exhibited a performance of 73.2% on HumanEval pass@1.
As explained, WizardCoder 34B represents a finely-tuned iteration of the Code Llama model utilizing the synthetic dataset Evol-Instruct.
The ensuing visualization contrasts the performance of all open source and closed source models.
When compared to OpenAI’s models, the researchers pointed out two HumanEval outcomes for GPT-4 and ChatGPT-3.5:
The results from OpenAI’s official GPT-4 report (dated 2023/03/15) are 67.0% and 48.1% respectively. In contrast, the researchers’ tests using the latest API (dated 2023/08/26) yielded results of 82.0% and 72.5%.
Furthermore, the researchers emphasize that these performance results are completely reproducible!
A demonstration of WizardCoder 34B is available for anyone to test.
It’s been noted that overfitting to public leaderboards remains a major hurdle for open source models. An example of data preparation for wizard-coder showcases the utilization of HumanEval pass@1 scores to determine the need for further dataset development. Focusing solely on the test set undermines the purpose of the test.
Also, on the preceding day, researchers from the Phind organization refined Code Llama-34B to surpass GPT-4 in the HumanEval assessment.
Comparing ChatGPT and Code Llama
How does Code Llama fare in real-world coding tasks?
An internet user conducted a comparative test between GPT-3.5 and Code Llama Instruct-34B using the access service provided by Perplexity.AI for Code Llama 34B.
They presented both models with eight identical coding tasks and evaluated the quality of their generated code.
- The outcome was an 8:5 victory for GPT-3.5.
- The ensuing details outline the test results for each question.
Regarding the performance comparison, the user stated that this was not a comprehensive study, but rather a simple test. Each time the model generated code, it generally produced a better answer. Consequently, the test’s conclusion isn’t indicative of the final performance of both models.
On Par with GPT-4, Llama 3 Remains Open Source
Since the introduction of Llama and Llama 2 Kaiyuan, the machine-learning community has witnessed a surge in ChatGPT replacements, with various fine-tuning models emerging.
Jason Wei, an OpenAI researcher, disclosed that Llama 3 and Llama 4 are set to be open source in the future, after the launch of Llama and Llama 2.
He stated, “We have the computing power to train Llama 3 and 4. Our plan is to make Llama-3 as good as GPT-4. If Llama-3 is as good as GPT-4, will you open-source it? Yes, we will.”
Another user suggested that Meta’s aim is to open source a model at the level of GPT-5, seemingly persisting with open source principles before AGI.
This user expressed concern about the implications of open sourcing-as AI becomes more sophisticated. They highlighted potential risks and the loss of control over AI systems.
According to available information, Meta’s inclination towards open source largely stems from the “open source community dogma.” Their proclivity for open source reportedly intensified after the accidental leak of their initial model, Llama, leading to a continued facade of openness.
In response, Musk criticized the energy inefficiency of autoregressive Transformer-based LLMs like Llama in both training and reasoning, indicating a substantial disparity compared to more efficient models.
- Llama 2’s Coding Proficiency Soars
- Llama 2 emerges as a formidable model on various fronts.
- However, it harbors a conspicuous weakness—its coding prowess.
According to data in Meta’s Llama 2 paper, Llama 2’s performance in HumEval (an encoding and LLM evaluation benchmark) lags behind not only GPT-3.5 but also GPT-4.
Yet, coding ability is set to be a pivotal focus for the open-source community’s utilization of Llama 2 in the future. Naturally, Meta cannot afford to be lacking in this aspect, leading to significant enhancements to Code Llama’s coding capabilities.
Recently, Meta unveiled the Code Llama family, including Code Llama (7B, 13B, and 34B) and three variants: the general code model Code Llama, the instruction follow model Code Llama-instruct, and the Python code-specific version Code Llama-Python.
These models are accessible for academic and commercial purposes, similar to Llama 2’s licensing terms.
The Code Llama 34B model boasts nearly twice the coding prowess of Llama 2, significantly narrowing the gap with GPT-4.
Recalling the Unnatural Code Llama from the Code Llama paper, which could match GPT-4’s capabilities, Sebastian clarified that it’s a fine-tuned version of Code Llama-Python 34B incorporating 15,000 non-natural language instructions.
This subtle hint by Meta in their paper seems to suggest that Code Llama harbors remarkable potential, encouraging further refinement.
Why isn’t there a 70B Code Llama model?
Interestingly, Code Llama is only available in 7B, 13B, and 34B parameter versions, significantly fewer than Llama 2’s 70B.
While Meta didn’t explicitly state the reasons for this in the paper, technology expert Sebastian proposed two possible explanations:
Code Llama is trained on 500B tokens, whereas Llama 2 is trained on 2T tokens.
With Code Llama’s training data comprising only a quarter of Llama 2’s data and considering the limitations of LLM’s Scaling Laws, the performance of a 70B Code Llama might be subpar.
The Code Llama model supports a context size of 100k, crucial for handling coding tasks.
In contrast, Llama 2 only supports input lengths up to 4k. Implementing a 70B model that supports a 100k-token input might lead to excessive computational requirements.
Do not forget to follow us on our Facebook group and page to keep you always aware of the latest advances, News, Updates, review, and giveaway on smartphones, tablets, gadgets, and more from the future technology world.